QUESTION
Task 1: Understanding of database
By relating your discussion to the above scenario where applicable,
-
Describe the differences between RDBMS and file based systems. Your discussion should include the advantages, disadvantages and limitations of each.
-
Discuss the advantages and disadvantages of Hierarchical, network and relational database models.
-
Discuss the strengths and weaknesses of top-down and bottom-up approaches to design/develop the database and justify the approach you will use for this task.
-
Identify all the possible entities that you can find in the problem scenario and list them in alphabetical order.
-
Using Crow’s foot notation, design a conceptual data model for the AutoSeller in a modeling tool of your choice. All entity types and the relationships between them must be clearly shown. Your design should show all cardinality and participation constraints accurately.
-
Discuss the principles of normalisation and demonstrate by examples the steps you followed to achieve normal forms in relation to the given scenario. Your demonstration must show the full process with explanations, starting from UNF, 1NF, 2NF to 3NF. (There is no requirement here to go through the full list of attributes in the data model for Auto Seller).
-
Produce an ERD with all the normalised entities containing the relevant attributes. State any de-normalisation, if any, in all your relations and clearly state the reasons for de-normalising relations in your implemented solution.
-
Map the ER model devised above into a set of logical relations in the relational data model.
Referencing and Bibliography
Although much of your report will make use of an existing body of knowledge, you must write your assignment with your own words to demonstrate your understanding of the subject. You are required to follow the Harvard referencing system when citing others’ work. An accompanying list of references must also be provided as part of your report. Extensively referenced work reflects the level of research you conducted in the process of producing the document. It is also an acknowledgement of other people’s work. Correct referencing demonstrates your academic and professional skill. It also reflects your academic honesty and thus to some degree protects you from cases of plagiarism.
Preparation Guidelines for Assignment Report
-
All components of the assignment report must be word processed (hand written text or hand drawn diagrams are not acceptable), font size must be within the range of 12 point to 14 point including the headings, body text and any texts within diagrams.
-
Standard and commonly used fonts such as Times New Roman, Arial or Calibri should be used.
-
Your document must be aligned left or justified with line spacing of 1.5.
-
All figures, graphs and tables must be numbered and labelled.
-
Material from external sources must be properly refereed and cited within the text using the Harvard referencing system.
-
All components of the assignment (text, diagrams. Code etc.) must be submitted in one pdf file
Plagiarism and Collusion
Any act of plagiarism (presenting another person’s published or unpublished work e.g. from a book or the web in any quantity without adequately identifying it and citing its source) or collusion (copying another learner’s assignment or work submitted by others in previous years and submitting it as your own effort) is academic misconduct and will be dealt with according to the regulations.
ANSWER
Task 1:
Q1. Differences between file-based systems and RDBMS:
-
A file-based system is a collection of files that store and manages data. On the other hand, a RDBMS is collection of relational data-bases.
-
File-based system has more data redundancy whereas there is less data redundancy in RDBMS.
-
File-based system provides less flexibility in accessing data, whereas RDBMS is more flexible in accessing data.
-
File-based system does not provide data consistency, whereas RDBMS provides data consistency through normalization.
-
File-based system is less complex, whereas RDBMS is more complex.
For complex and large operations, the file–system not suitable r be used as it is very slow.
Advantage of the File-based System over Relational Data base Management System are:
File System are best suited for unrelated data or small data. Simple operations like read, write, etc. is faster in File System.
Cost: Installation and Maintenance charges of RDBMS is higher which doesn’t fit in budget of small organizations.One have to purchase a software and in many cases they need to hire a professional programmer who have good experienced in coding and/or SQL. Once the database is ready, information is entered or imported from existing database which is time consuming and expensive as well. If database contains information that is sensitive, like credit card/debit card numbers or Social Security numbers, one have to ensure that the information is secured and only unauthorized users can access it, which is again expensive to implement.
Limitations in Structure: RDBMS imposes restriction on the length of data that is entered means if you enter large amount of information which is beyond its limit then important information may be lost.
Isolated Information: Since RDBMS uses large number of tables and there is a high risk that some of the important information/data might be lost while the transferring of the data from one computer to another. This is one of the major problem faced by large organizations.
Q2. The advantages and disadvantages of Hierarchical, network and relational database models.
In the hierarchical model, data is stored in hierarchy. For eg. , a company consists departments and each department has employees. Hence, a tree structure is created where the company is at the root of the tree. To reach all the employees in the company, one have to traverse the entire tree.
To address the inefficiencies of the Hierarchical model, Network Model was tried. In Network Model, one can create a network which can show the relation b/w data but Network model was also dropped and was eventually replaced by Relational Model.
The relational model (RM) for database management is an approach to managing data using a structure and language consistent with first-order predicate logic, first described in 1969 by English computer scientist Edgar F. Codd, where all data is represented in terms of tuples, grouped into relations.[7] The Relational Model is the most efficient and flexible database model which is currently used in many firms.
Q3.
Bottom up approach, basically begins with the concrete design to get abstract entity. It is majorly used for small organizations or small section of large organization. It is used where the number of attribute is small and the number of entities are small too with less relationships. It generally holds less volume of data. It begins with defining attributes then entities and then conceptual schema.
When database is being designed by the designer for some larger organization, we starts planning with overall requirement of data for the database. We start looking for entities about the data that we will be required and will be stored in the database and then we start looking for the attributes. In general, we have very large no of entities in a relation and there might be large no of relationship between them. This leads to very complex database with very large amount of data. To overcome this we use top-down approach. In this we start with looking for the entities for the database followed by the attributes that we will need to store important data.
In this case we will use bottom-up approach as it will be better and easy to understand the important requirement and then moving upward to higher level of the schema.
Task 2:
Q1. All the possible entities that present in problem scenario are:
-
Buyer
-
Buyer_contact
-
Car
-
Car_detail
-
Order
-
Seller
-
Seller_contact
Q2.

Task3
Q1.
1NF:
(where there are multiple values in one cell)
single user can have multiple contact number, break it into multiple rows.
2NF:
(where there are multiple rows because of one or two different attribute)
Saperate the table made for buyer_contact and seller_contact, successfully converted to 2NF form.
3NF:
(when some non-key attribute is function of another non key attribute)
Data like price which is not dependent on the car_id(in car table) is removed form car table or is placed in car_detail (which is more appropriate).
Q2.
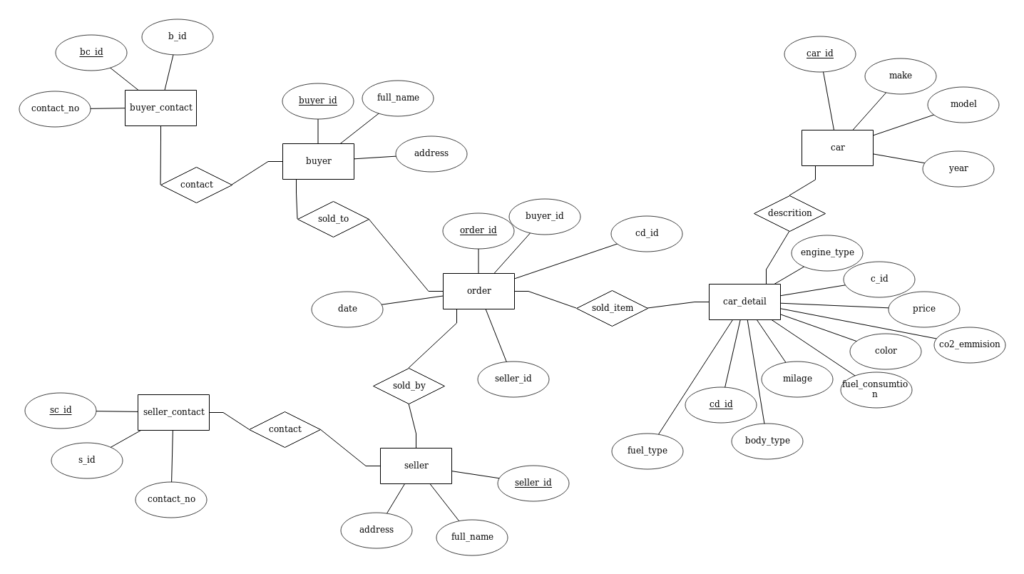
Q3.
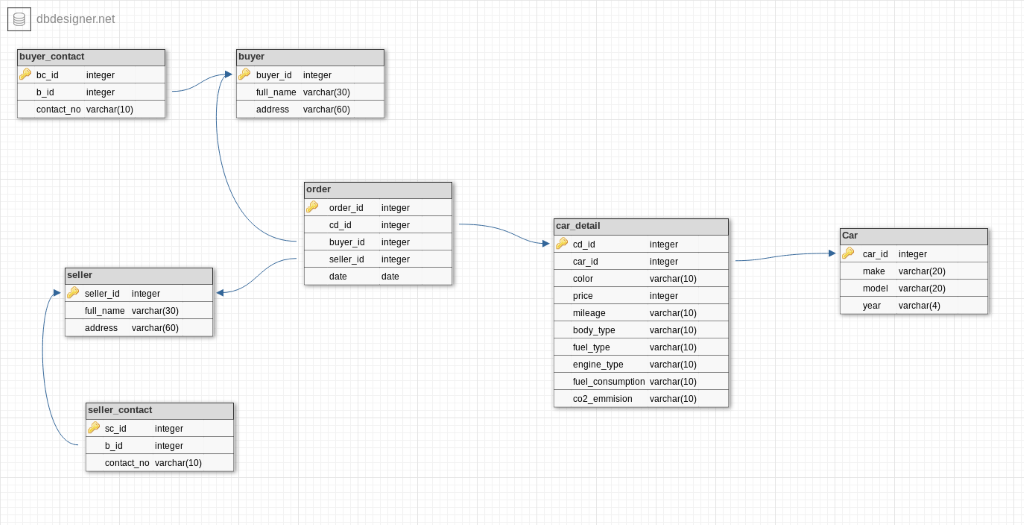
Bibliography:
[1] David Weedmark; December 04, 2018; Limitations of Relational Databases; https://smallbusiness.chron.com/limitations-relational-databases-business-applications-24159.html
[2] Advantages and disadvantages of top-down and bottom-up model; https://publib.boulder.ibm.com/tividd/td/ITIM/SC32-1708-00/en_US/HTML/im460_plan76.htm
[3] Mike Chapple; January 04, 2019; Database Normalization Basics; https://www.lifewire.com/database-normalization-basics-1019735
[4]https://www.google.com/search?client=ubuntu&hs=8lq&channel=fs&biw=1299&bih=599&tbm=isch&sa=1&ei=5zBsXL3vH8XVmAWY6aCwDQ&q=relational+model&oq=relation+model&gs_l=img.3.0.0i10l10.3355.7156..8784…2.0..0.272.2146.0j11j1……1….1..gws-wiz-img…….0j0i7i30j0i67.3oC4tXjO3QA#imgrc=RwYbM5kxVg-SCM:
[5] https://www.javatpoint.com/sql-insert-multiple-rows
[6] Oracle Database 12c Hands-On SQL and PL/SQL; Satish Asnani ; 2016
[7] https://en.wikipedia.org/wiki/Relational_model
Looking for best Computer Science Assignment Help. Whatsapp us at +16469488918 or chat with our chat representative showing on lower right corner or order from here. You can also take help from our Live Assignment helper for any exam or live assignment related assi